Research
Novelty Measurement
Automated Novelty Evaluation of Academic Paper: A Collaborative Approach Integrating Human and Large Language Model Knowledge
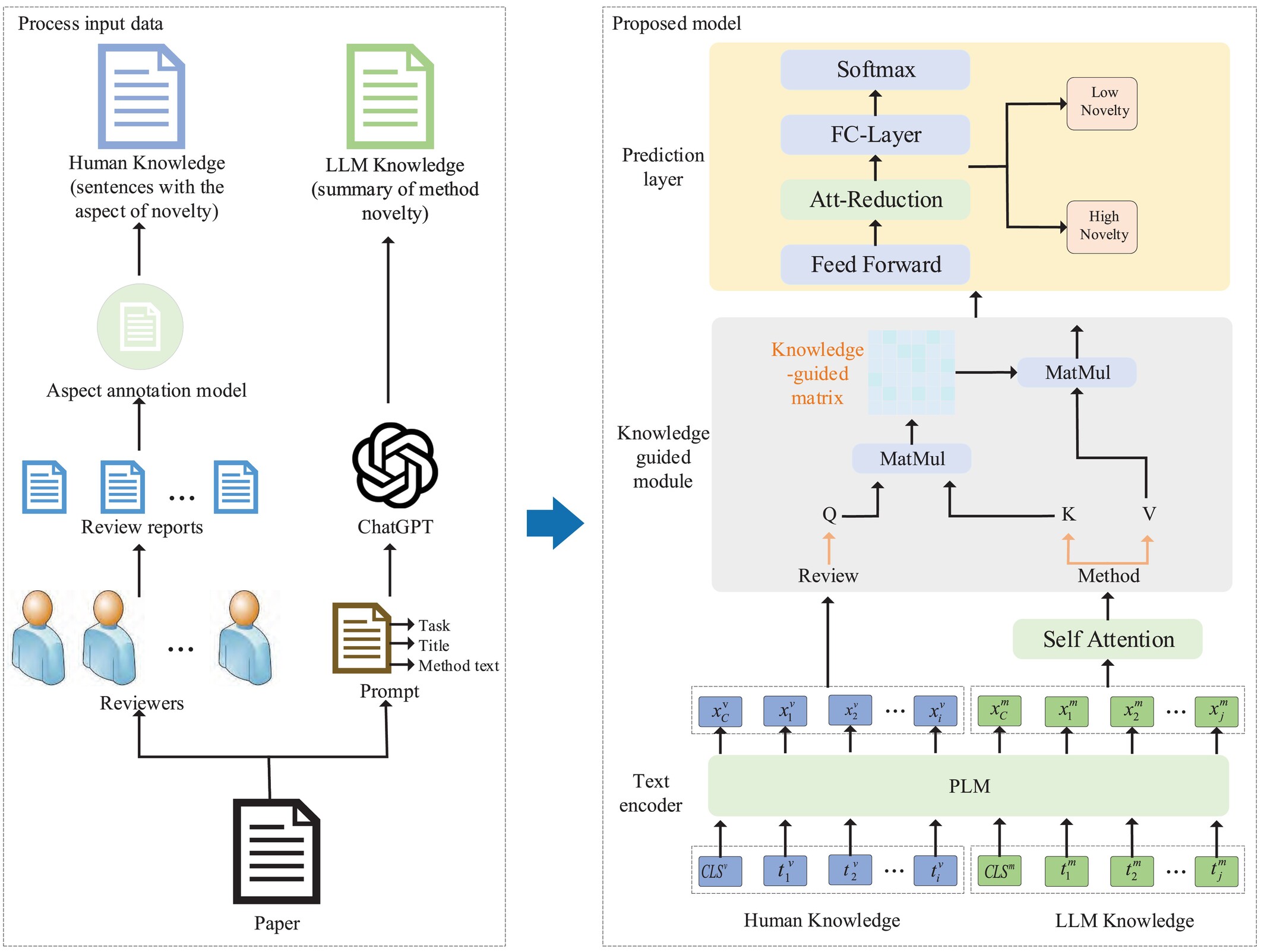 Novelty is vital in peer review but is hard to measure: expert judgment is limited, and citation-based metrics may not truly reflect novelty. Large language models (LLMs) offer extensive knowledge, while human experts provide nuanced judgment. To address their respective limitations, we combine both in a hybrid approach for assessing methodological novelty in academic papers. Our method extracts novelty-related sentences from peer reviews and uses LLMs to summarize the methodology section. These outputs help fine-tune pretrained language models (PLMs) like BERT. We also introduce a text-guided fusion module with Sparse-Attention to integrate human and LLM insights. Experiments show our approach outperforms strong baselines.
Novelty is vital in peer review but is hard to measure: expert judgment is limited, and citation-based metrics may not truly reflect novelty. Large language models (LLMs) offer extensive knowledge, while human experts provide nuanced judgment. To address their respective limitations, we combine both in a hybrid approach for assessing methodological novelty in academic papers. Our method extracts novelty-related sentences from peer reviews and uses LLMs to summarize the methodology section. These outputs help fine-tune pretrained language models (PLMs) like BERT. We also introduce a text-guided fusion module with Sparse-Attention to integrate human and LLM insights. Experiments show our approach outperforms strong baselines.
Wenqing Wu, Chengzhi Zhang*, Yi Zhao. Automated Novelty Evaluation of Academic Paper: A Collaborative Approach Integrating Human and Large Language Model Knowledge. Journal of the Association for Information Science and Technology. 2025, 76(11): 1452-1469. [doi] [arXiv] [Dataset & Source Code] [Information Matters]
Scientific Text Mining
Examining scientific writing styles from the perspective of linguistic complexity
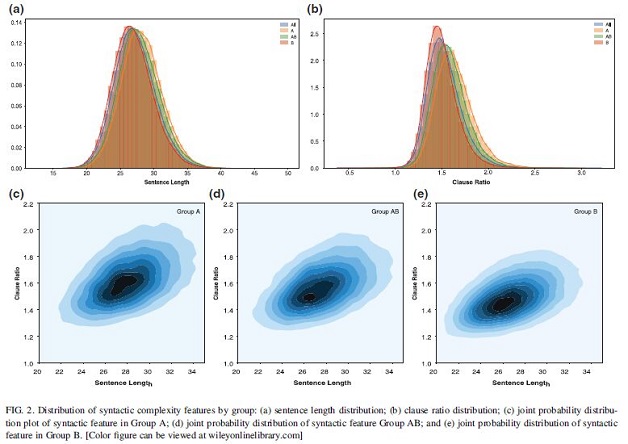 To uncover the differences in English scientific writing between native English-speaking scholars (NESs) and non-native English-speaking scholars (NNESs), we collected a large-scale data set containing more than 150,000 full-text articles published in PLoS between 2006 and 2015. We divided these articles into three groups according to the ethnic backgrounds of the first and corresponding authors, obtained by Ethnea, and examined the scientific writing styles in English from a two-fold perspective of inguistic complexity: syntactic and lexical complexity. The observations suggest marginal differences between groups in syntactical and lexical complexity.
To uncover the differences in English scientific writing between native English-speaking scholars (NESs) and non-native English-speaking scholars (NNESs), we collected a large-scale data set containing more than 150,000 full-text articles published in PLoS between 2006 and 2015. We divided these articles into three groups according to the ethnic backgrounds of the first and corresponding authors, obtained by Ethnea, and examined the scientific writing styles in English from a two-fold perspective of inguistic complexity: syntactic and lexical complexity. The observations suggest marginal differences between groups in syntactical and lexical complexity.
Chao Lu, Yi Bu, Jie Wang, Ying Ding, Vetle Torvik, Matthew Schnaars, Chengzhi Zhang*. Examining scientific writing styles from the perspective of linguistic complexity. Journal of the Association for Information Science and Technology, 2019, 70(5):462-475. [doi]
Examining linguistic shifts in academic writing before and after the launch of ChatGPT: a study on preprint papers
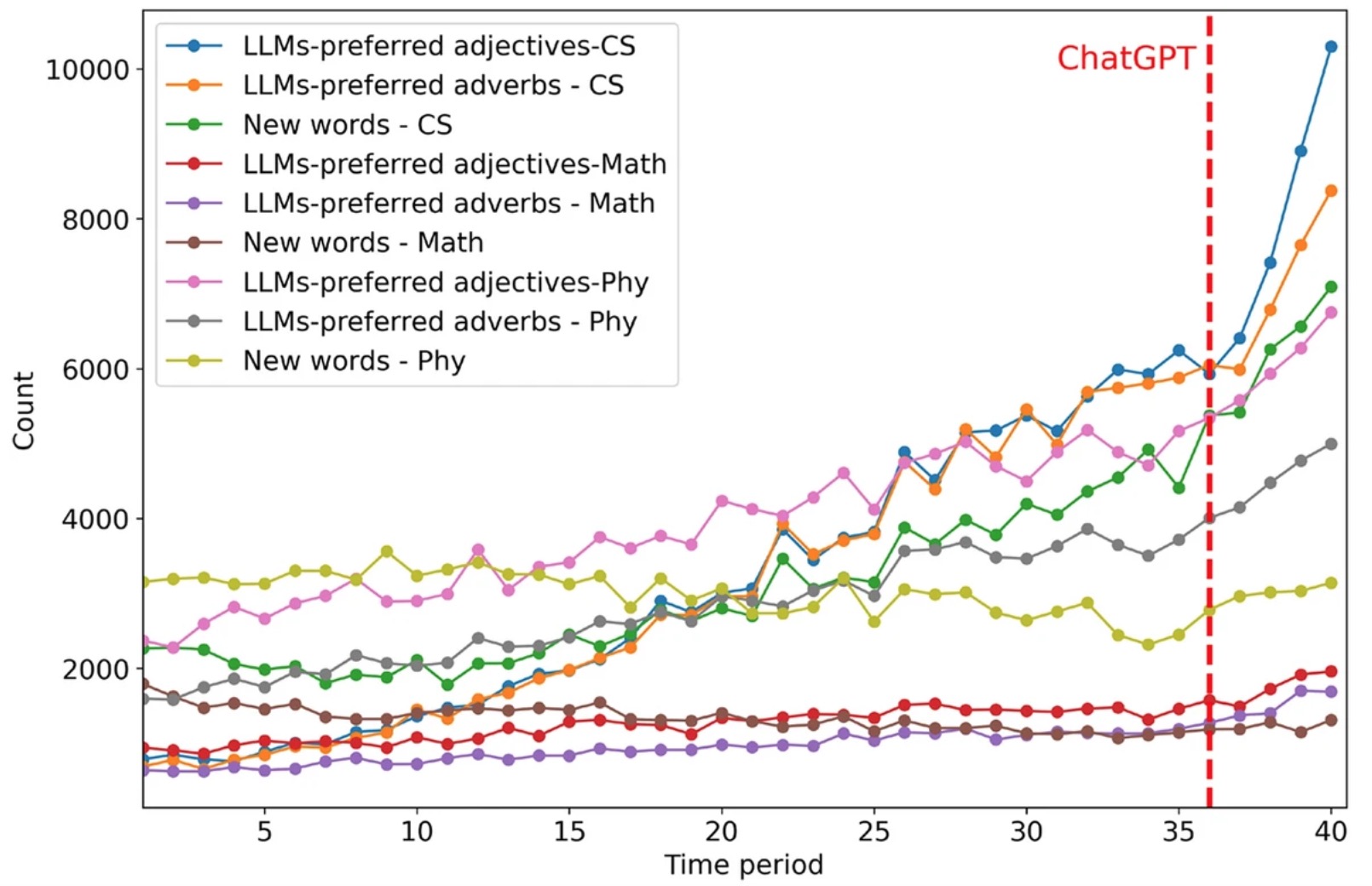 Large Language Models (LLMs) like ChatGPT have raised concerns about their influence on academic writing. Prior studies mainly used quantitative methods but rarely explored how LLMs affect linguistic characteristics. To fill this gap, we analyzed 823,798 arXiv abstracts from the past decade. Results show a sharp rise in LLM-preferred word usage, indicating widespread LLM influence. Lexical complexity and sentiment increased, while syntactic complexity, cohesion, and readability declined. This suggests LLMs promote richer vocabulary and simpler structures, but reduce clarity. Notably, non-native English speakers used LLMs more, aiming to improve fluency. Disciplinary differences were also evident, with stronger stylistic shifts in Computer Science than in Mathematics.
Large Language Models (LLMs) like ChatGPT have raised concerns about their influence on academic writing. Prior studies mainly used quantitative methods but rarely explored how LLMs affect linguistic characteristics. To fill this gap, we analyzed 823,798 arXiv abstracts from the past decade. Results show a sharp rise in LLM-preferred word usage, indicating widespread LLM influence. Lexical complexity and sentiment increased, while syntactic complexity, cohesion, and readability declined. This suggests LLMs promote richer vocabulary and simpler structures, but reduce clarity. Notably, non-native English speakers used LLMs more, aiming to improve fluency. Disciplinary differences were also evident, with stronger stylistic shifts in Computer Science than in Mathematics.
Tong Bao, Yi Zhao, Jin Mao, Chengzhi Zhang*. Examining Linguistic Shifts in Academic Writing Before and After the Launch of ChatGPT: A Study on Preprint Papers. Scientometrics, 2025 (in press) [doi] [arXiv] [THE news]
Usage frequency and application variety of research methods in library and information science: Continuous investigation from 1991 to 2021
 Over 26,000 research articles published between 1991 and 2021 in twenty-one major LIS journals were analyzed, using the machine learning (ML) approach to categorize the research methods used by LIS scholars. The findings of this study are significant. Firstly, there has been a shift in the research strategy from conceptual research to empirical research in LIS investigations over the past 31 years. Secondly, the research topics explored by LIS scholars during this period have moved from system-centered issues to user-centered topics. Thirdly, the study revealed dynamic and revealing relationships between the 18 research topics identified in the study and the 16 research methods commonly adopted in the LIS field.
Over 26,000 research articles published between 1991 and 2021 in twenty-one major LIS journals were analyzed, using the machine learning (ML) approach to categorize the research methods used by LIS scholars. The findings of this study are significant. Firstly, there has been a shift in the research strategy from conceptual research to empirical research in LIS investigations over the past 31 years. Secondly, the research topics explored by LIS scholars during this period have moved from system-centered issues to user-centered topics. Thirdly, the study revealed dynamic and revealing relationships between the 18 research topics identified in the study and the 16 research methods commonly adopted in the LIS field.
Chengzhi Zhang*, Liang Tian, Heting Chu. Usage Frequency and Application Variety of Research Methods in Library and Information Science: Continuous investigation from 1991 to 2021. Information Processing and Management, 2023, 60(6): 103507. [doi] [Demo]
Knowledge Entity Extraction and Evaluation
Revealing the Technology Development of Natural Language Processing: A Scientific Entity-Centric Perspective
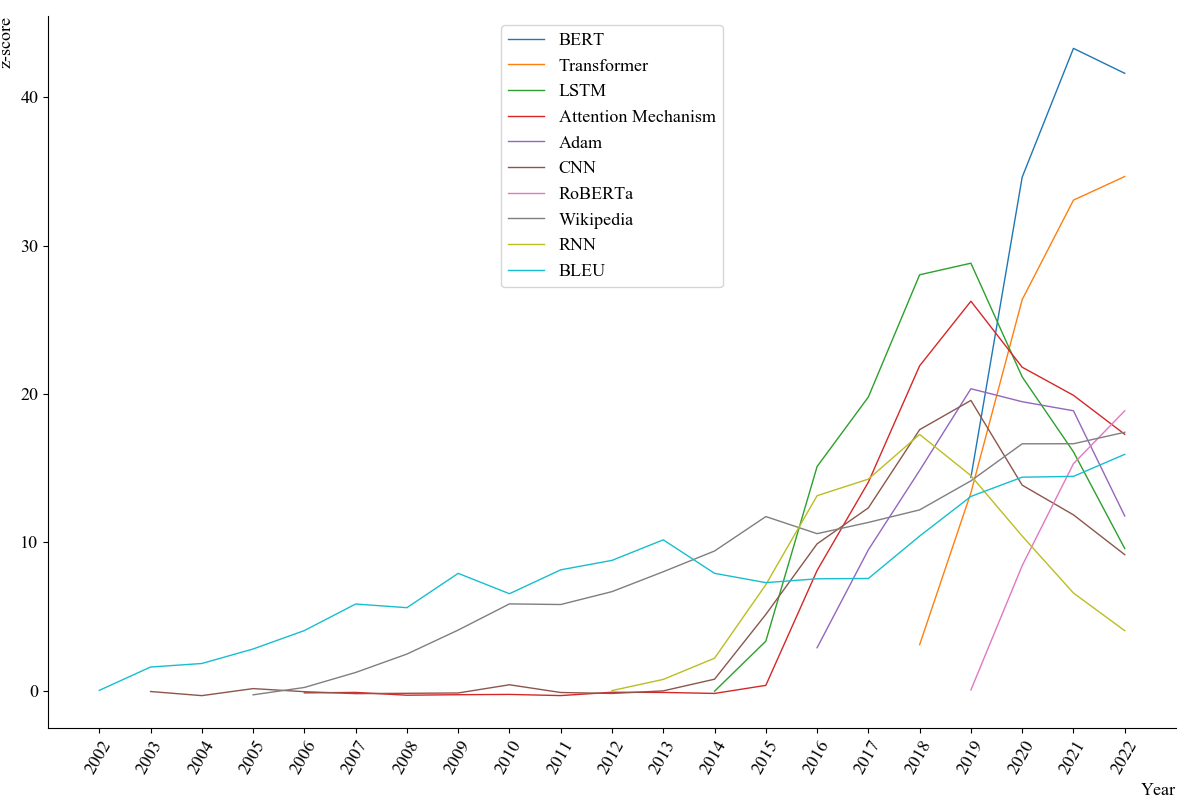 We extract technology-related entities—methods, datasets, metrics, and tools—from NLP papers and apply a semi-automatic normalization process. Using co-occurrence networks, we compute z-scores to evaluate entity impact and analyze technology trends in NLP since the early 2000s. Our findings include: (1) The rising average number of entities per paper indicates increasing demands on researchers’ technical knowledge, though the rise of pre-trained language models has revitalized innovation. (2) Methods dominate the 179 high-impact entities, with BERT and Transformer leading recent trends. (3) In recent years, high-impact technologies have gained popularity and researcher adoption at unprecedented speeds.
We extract technology-related entities—methods, datasets, metrics, and tools—from NLP papers and apply a semi-automatic normalization process. Using co-occurrence networks, we compute z-scores to evaluate entity impact and analyze technology trends in NLP since the early 2000s. Our findings include: (1) The rising average number of entities per paper indicates increasing demands on researchers’ technical knowledge, though the rise of pre-trained language models has revitalized innovation. (2) Methods dominate the 179 high-impact entities, with BERT and Transformer leading recent trends. (3) In recent years, high-impact technologies have gained popularity and researcher adoption at unprecedented speeds.
Heng Zhang, Chengzhi Zhang*, Yuzhuo Wang. Revealing the Technology Development of Natural Language Processing: A Scientific Entity-Centric Perspective. Information Processing and Management, 2024, 61(1): 103574. [doi] [Dataset & Source Code]
Using the Full-text Content of Academic Articles to Identify and Evaluate Algorithm Entities in the Domain of Natural Language Processing
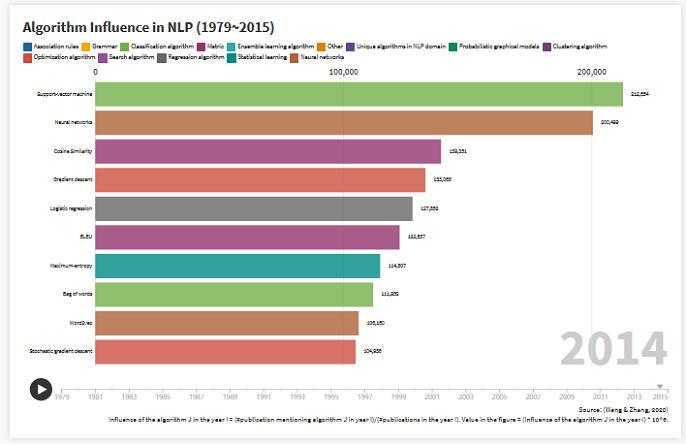 Taking NLP as an example, we manually annotate the more algorithm entities with specific names in academic papers, and evaluate the influence of the algorithm based on the number of papers mentioning an algorithm and duration of mention. We analyze the changes of the algorithms with high impact in different years, and explore the evolution of the algorithm influence over time. Algorithm entities and sentences mentioning these algorithms identified by this work can be used as a training corpus for automatic extraction of the algorithmic entities.
Taking NLP as an example, we manually annotate the more algorithm entities with specific names in academic papers, and evaluate the influence of the algorithm based on the number of papers mentioning an algorithm and duration of mention. We analyze the changes of the algorithms with high impact in different years, and explore the evolution of the algorithm influence over time. Algorithm entities and sentences mentioning these algorithms identified by this work can be used as a training corpus for automatic extraction of the algorithmic entities.
Yuzhuo Wang, Chengzhi Zhang*. Using the Full-text Content of Academic Articles to Identify and Evaluate Algorithm Entities in the Domain of Natural Language Processing. Journal of Informetrics, 2020, 14(4): 101091.[doi] [arxiv] [Demo: Algorithm Influence in NLP (1979~2015)] [Video]
Keyphrase Extraction
Enhancing Keyphrase Extraction from Microblogs using Human Reading Time
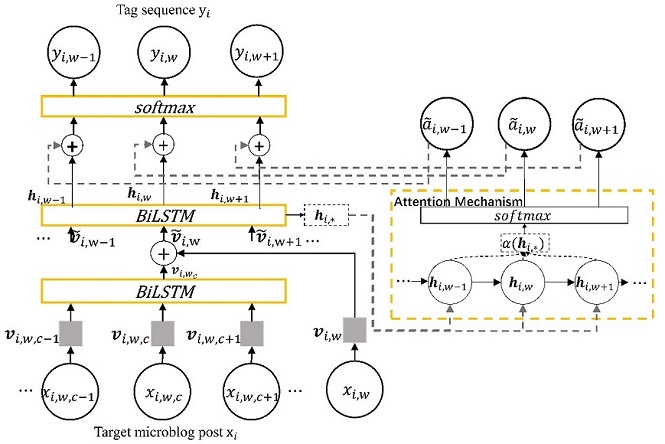 We aim to leverage human reading time to extract keyphrases from microblog posts. There are two main tasks in this study. One is to determine how to measure the time spent by a human on reading a word. We use eye fixation durations extracted from an open source eye-tracking corpus (OSEC). Moreover, we propose strategies to make eye fixation duration more effective on keyphrase extraction. The other task is to determine how to integrate human reading time into keyphrase extraction models. We propose two novel neural network models. The first is a model in which the human reading time is used as the ground truth of the attention mechanism. In the second model, we use human reading time as the external feature.
We aim to leverage human reading time to extract keyphrases from microblog posts. There are two main tasks in this study. One is to determine how to measure the time spent by a human on reading a word. We use eye fixation durations extracted from an open source eye-tracking corpus (OSEC). Moreover, we propose strategies to make eye fixation duration more effective on keyphrase extraction. The other task is to determine how to integrate human reading time into keyphrase extraction models. We propose two novel neural network models. The first is a model in which the human reading time is used as the ground truth of the attention mechanism. In the second model, we use human reading time as the external feature.
Yingyi Zhang, Chengzhi Zhang*. Enhancing Keyphrase Extraction from Microblogs using Human Reading Time. Journal of the Association for Information Science and Technology, 2021, 72(5): 611-626. [doi] [arxiv]
Joint Modeling of Characters, Words, and Conversation Contexts for Microblog Keyphrase Extraction
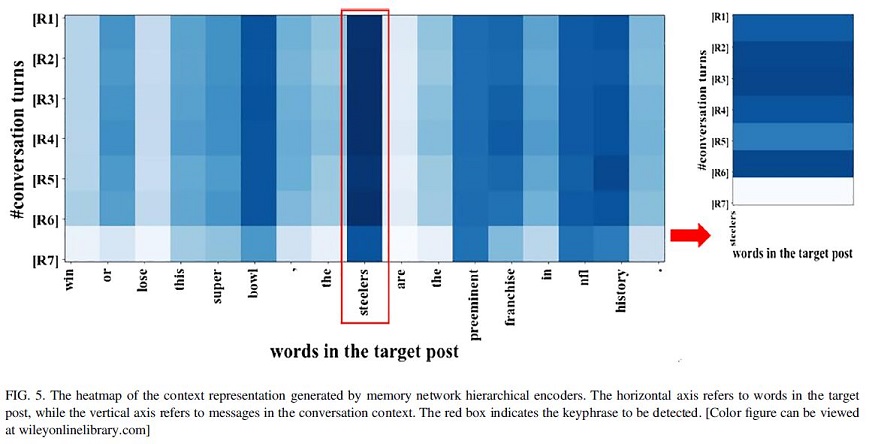 We propose a neural keyphrase extraction framework for microblog posts. The framework consists of two modules: a conversation context encoder and a keyphrase tagger. Conversation context encoders are utilized to encode conversation context to help keyphrase taggers indicate salient phrases. The keyphrase tagger is employed to extract keyphrases from target posts. To leverage the structure of conversation, the hierarchical encoder is employed to learn the word-level and message-level information from a conversation context. To alleviate the OOV problem in usergenerated content on social media platforms, we utilized the character-level word embedding to capture both characterlevel and word-level features in both conversation context encoders and keyphrase taggers.
We propose a neural keyphrase extraction framework for microblog posts. The framework consists of two modules: a conversation context encoder and a keyphrase tagger. Conversation context encoders are utilized to encode conversation context to help keyphrase taggers indicate salient phrases. The keyphrase tagger is employed to extract keyphrases from target posts. To leverage the structure of conversation, the hierarchical encoder is employed to learn the word-level and message-level information from a conversation context. To alleviate the OOV problem in usergenerated content on social media platforms, we utilized the character-level word embedding to capture both characterlevel and word-level features in both conversation context encoders and keyphrase taggers.
Yingyi Zhang, Chengzhi Zhang*, Jing Li. Joint Modeling of Characters, Words, and Conversation Contexts for Microblog Keyphrase Extraction. Journal of the Association for Information Science and Technology, 2020, 71(5):553-567. [doi]
Utilizing Cognitive Signals Generated during Human Reading to Enhance Keyphrase Extraction from Microblogs
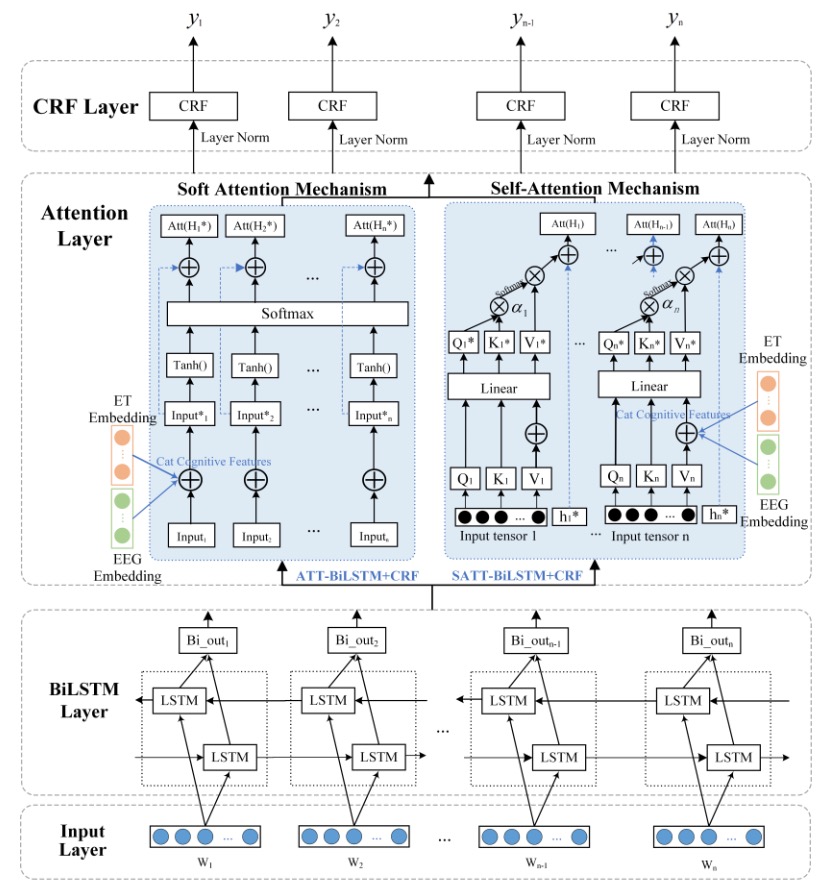 We propose the integration of electroencephalogram (EEG) signals with eye-tracking signals to improve Automatic Keyphrase Extraction (AKE) from Microblogs. Our first step is identifying specific features present in cognitive signals generated during human reading. We selected EEG signals (8 features) and eye-tracking signals (17 features) from the cognitive language processing corpus ZUCO, to examine the efficacy when they are combined with the Microblogs-based AKE. To avoid cognitive signal distortion by certain model structures, we introduced these signals at the inputs of the soft attention layer and at the query vectors of the self-attention layer. For evaluation, we performed several AKE tests on Microblogs with various combinations of cognitive signals. The results demonstrate a consistent enhancement in the performance of AKE due to cognitive signals generated during human reading, regardless of different feature combinations and models.
We propose the integration of electroencephalogram (EEG) signals with eye-tracking signals to improve Automatic Keyphrase Extraction (AKE) from Microblogs. Our first step is identifying specific features present in cognitive signals generated during human reading. We selected EEG signals (8 features) and eye-tracking signals (17 features) from the cognitive language processing corpus ZUCO, to examine the efficacy when they are combined with the Microblogs-based AKE. To avoid cognitive signal distortion by certain model structures, we introduced these signals at the inputs of the soft attention layer and at the query vectors of the self-attention layer. For evaluation, we performed several AKE tests on Microblogs with various combinations of cognitive signals. The results demonstrate a consistent enhancement in the performance of AKE due to cognitive signals generated during human reading, regardless of different feature combinations and models.
Xinyi Yan, Yingyi Zhang, Chengzhi Zhang*. Utilizing Cognitive Signals Generated during Human Reading to Enhance Keyphrase Extraction from Microblogs. Information Processing and Management, 2024, 61(2): 103614. [doi] [Dataset & Source Code]
Social Media Mining
Using social media to explore regional cuisine preferences in China
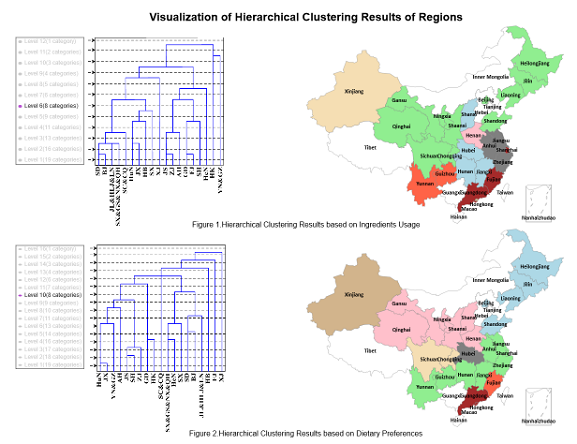 Based on both UGC and online recipes, we first investigated the cuisine preference distribution in different regions. Then, dish preference similarity between regions was calculated and few geographic factors were identified, which might lead to such regional similarity appeared in our study. By applying hierarchical clustering, we clustered regions based on dish preference and ingredient usage separately.Different from traditional definitions of regions to which cuisine belong, we found new association between region and cuisine based on dish preference from social media and ingredient usage of dishes. Using social media may overcome problems with using traditional questionnaires, such as high costs and long cycle for questionnaire design and answering.
Based on both UGC and online recipes, we first investigated the cuisine preference distribution in different regions. Then, dish preference similarity between regions was calculated and few geographic factors were identified, which might lead to such regional similarity appeared in our study. By applying hierarchical clustering, we clustered regions based on dish preference and ingredient usage separately.Different from traditional definitions of regions to which cuisine belong, we found new association between region and cuisine based on dish preference from social media and ingredient usage of dishes. Using social media may overcome problems with using traditional questionnaires, such as high costs and long cycle for questionnaire design and answering.
Chengzhi Zhang*, Zijing Yue, Qingqing Zhou, Shutian Ma, Zike Zhang. Using social media to explore regional cuisine preferences in China. Online Information Review. 2019, 43(7): 1098-1114. [doi] [Demo]
